fastp软件的使用
本文最后更新于 2025年2月7日 下午
fastp: A tool designed to provide fast all-in-one preprocessing for FastQ files. This tool is developed in C++ with multithreading supported to afford high performance.
fastp,它可以仅仅扫描FASTQ文件一次,就完成比FASTQC + cutadapt + Trimmomatic 这三个软件加起来的功能还多很多的功能,而且速度上比仅仅使用Trimmomatic一个软件还要快3倍左右,因为它使用C++开发,处处使用了高效算法,而且完美支持多线程!
fastp过滤测序序列
过滤
fastp可以对低质量序列,较多N的序列,该功能默认是启用的,但可以使用-Q参数关闭。使用-q参数来指定合格的phred质量值,比如-q 15表示质量值大于等于Q15的即为合格,然后使用-u参数来指定最多可以有多少百分比的质量不合格碱基。比如-q 15 -u 40表示一个read最多只能有40%的碱基的质量值低于Q15,否则会被扔掉。使用-n可以限定一个read中最多能有多少个N。
fastp还默认启用了read长度过滤,但可以使用-L参数关闭。使用-l参数指定最低要求一个read有多长,比如-l 30表示低于30个碱基的read会被扔掉。这个功能可以用于实现常用的discard模式,以保证所有输出的序列都一样长。
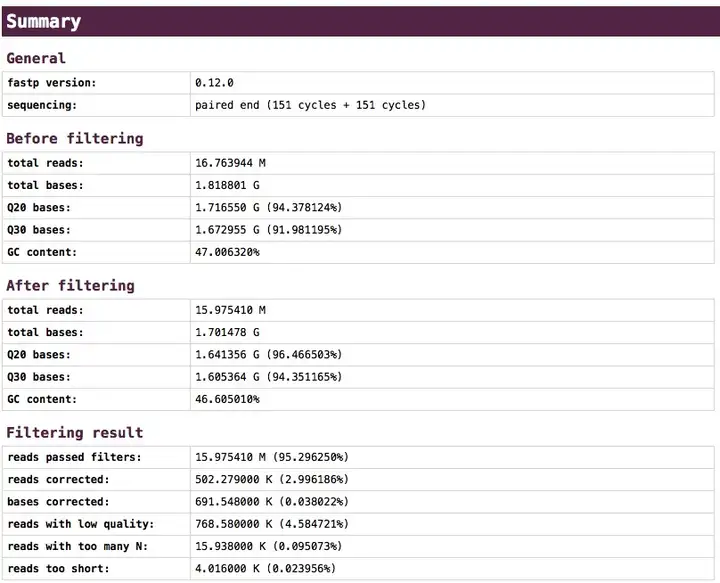
在fastp的HTML报告中,最头上的Summary表格很清楚地显示了过滤的统计信息,如下图所示:
接头处理
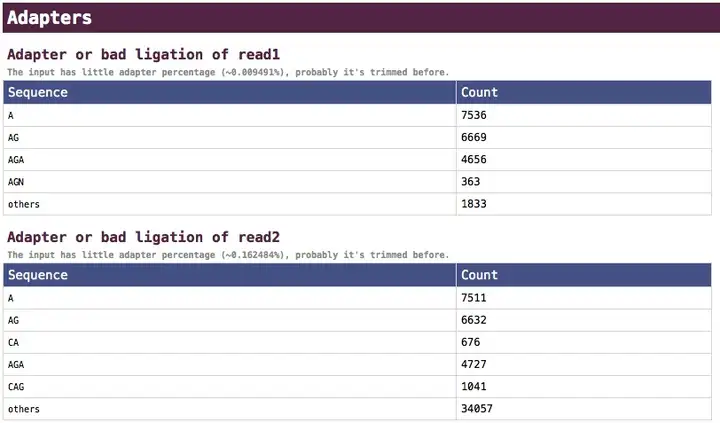
接头(adapter)污染的处理是FASTQ文件预处理中很重要的一步。fastp默认启用了接头处理,但是可以使用-A命令来关掉。fastp可以自动化地查找接头序列并进行剪裁,也就是说你可以不输入任何的接头序列,fastp全自动搞定了!对于SE数据,你还是可以-a参数来输入你的接头,而对于PE数据则完全没有必要,fastp基于PE数据的overlap分析可以更准确地查找接头,去得更干净,而且对于一些接头本身就有碱基不匹配情况处理得更好。fastp对于接头去除会有一个汇总的报告,如下图所示:
滑窗质量剪裁
很多时候,一个read的低质量序列都是集中在read的末端,也有少部分是在read的开头。fastp支持像Trimmomatic那样对滑动窗口中的碱基计算平均质量值,然后将不符合的滑窗直接剪裁掉。使用-5参数开启在5’端,也就是read的开头的剪裁,使用-3参数开启在3’端,也就是read的末尾的剪裁。使用-W参数指定滑动窗大小,默认是4,使用-M参数指定要求的平均质量值,默认是20,也就是Q20。
PE数据的碱基校正
fastp支持对PE数据的每一对read进行分析,查找它们的overlap区间,然后对于overlap区间中不一致的碱基,如果发现其中一个质量非常高,而另一个非常低,则可以将非常低质量的碱基改为相应的非常高质量值的碱基值,如下图所示:

上图中所示的标红的T碱基是低质量序列,和高质量的A不匹配,它会被校正为A。该校正功能默认没有开启使用-c参数可以启用,对于一些对噪声容忍度低的应用,比如液体活检,建议开启。
全局剪裁
fastp可以对所有read在头部和尾部进行统一剪裁,该功能在去除一些测序质量不好的cycle比较有用,比如151*2的PE测序中,最后一个cycle通常质量是非常低的,需要剪裁掉。使用-f和-t分别指定read1的头部和尾部的剪裁,使用-F和-T分别指定read2的头部和尾部的剪裁。
polyG剪裁
对于两色发光法的Illumina设备(NextSeq / NovaSeq),因为在没有光信号情况下base calling的结果会返回G,所以在序列的尾端可能会出现较多的polyG,需要被去除。fastp会自动化地识别NextSeq / NovaSeq的数据,然后进行polyG识别和剪裁。如果你想强制开启该功能,可以指定-g参数,如果想强制关闭该功能,则可以指定-G参数。
分子标签UMI处理
UMI在处理ctDNA类似的超低频突变检测应用中是十分有用的,为了更好地对带UMI的FASTQ文件进行预处理,fastp也很好地支持了UMI预处理功能。该功能默认没有启用,需要使用-U参数开启,另外需要使用–umi_loc来指定UMI所在的位置,它可以是(index1、 index2、 read1、 read2、 per_index、 per_read )中的一种,分别表示UMI是在index位置上,还是在插入片段中。如果指定了是在插入序列中,还需要使用 --umi_len 参数来指定UMI所占的碱基长度。
输出文件切分
很多时候我们需要对输出的FASTQ进行切分,分成大小均匀的多个文件,这样可以使用比对软件并行地比对,提高并行处理的速度。fastp软件也提供了相应的功能,并且支持了两种模式,分别是使用参数-s指定切分后文件的个数,或者使用-S参数指定每个切分后文件的行数。
质控报告解读
接下来,我们再看一下如何理解fastp生成的质控报告。fastp的报告在单一文件中同时包含了过滤前和过滤后的统计结果,如果是PE数据,则同时包含了read1和read2的统计结果。之前我们已经说过了,fastp会生成HTML的报告和JSON格式的报告。HTML报告的默认文件名是fastp.html,但是可以通过-h参数修改,JSON报告的默认文件名是fastp.json,但是可以通过-j参数修改。而且fastp报告还有一个标题,默认是fastp report,这个也可以通过-R参数修改为你想要的标题。JSON格式的报告是优化过的,人机皆可读,适合进阶的用户使用程序解析,而这里我们重点关注HTML格式的报告。
质量分布曲线图
我们第一关注的当然是质量,所以fastp提供了质量分布曲线,即每一个cycle的平均质量值,而且fastp同时提供了A/T/C/G四种不同碱基的平均质量,以及总的平均质量,如下图所示:
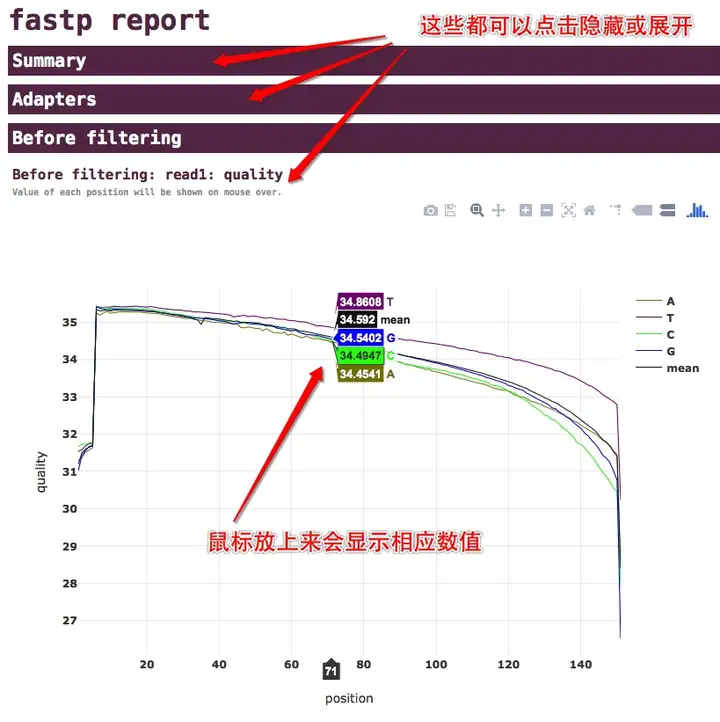
从上图我们可以看到,一共有5条曲线,分别是A/T/C/G和mean。而且HTML报告中的每一个项目和分项目都是可以点击进行隐藏和展开的。
碱基含量分布曲线
和质量分布曲线类似,碱基含量分布曲线也是按照每一个cycle来的,显示了每一个位置的碱基含量。如下图所示:
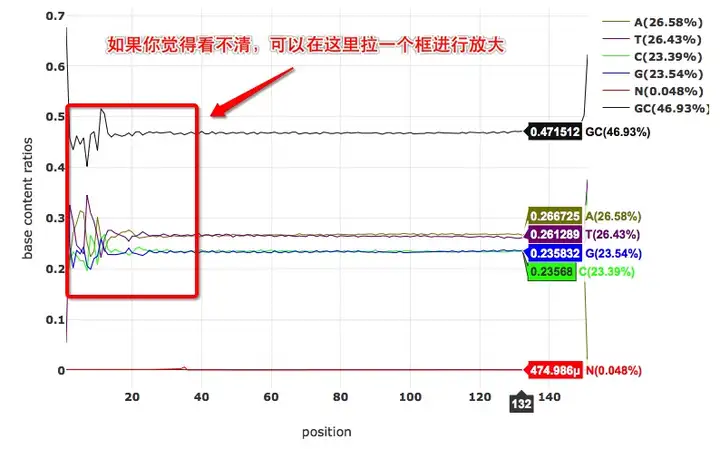
从图中可以看到,fastp同时显示了A/T/C/G/N/GC
的每一个位置的比例和总的比例。而且如果你觉得头部那里比较乱看不清的话,可以用鼠标拉一个框,它就放大了。
KMER统计表格
fastp对5个碱基长度的所有组合的出现次数进行了统计,然后把它放在了一张表格中,表格的每一个元素为深背景白字,背景越深,则表示重复次数越多。这样,一眼望去,就可以发现有哪一些异常的信息。

从上面的KMER表格中,我们可以发现,GGGGG的颜色特别深,从鼠标移上去之后显示的信息中我们可以发现它的出现次数是平均次数的12.8倍,这是不正常的,因为GGGGG的正常倍数应该在1倍左右。幸好我们有fastp,它可以过滤掉这种polyG,让数值较多地回归正常。
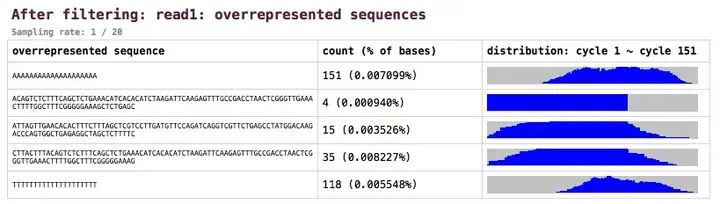
过表达序列(overrepresented sequence)
fastp的最新版本(v0.12)提供了overrepresetned
sequence的分析,而且不但提供了这些overrepresented sequence的序列个数和占比,还提供了他们在测序cycles中的分布情况,这有利于分析各种问题。具体示例如下图所示: